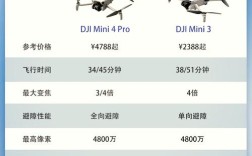
Dobby无人机是由零度智控(ZEROTECH)推出的消费级无人机,因此它的官方App名称是 “零度智控” 或 “ZEROTECH”,而不是一个叫做“Dobby”的独立App。

(图片来源网络,侵删)
您需要下载的是“零度智控”官方App来连接和控制您的Dobby无人机。
官方App下载渠道
为了确保App的安全、稳定和功能完整,强烈建议您通过以下官方渠道下载:
苹果手机用户
- App Store:在App Store中直接搜索 “零度智控” 或 “ZEROTECH”,找到由“零度智控(北京)科技有限公司”开发的官方App进行下载。
安卓手机用户
由于安卓应用商店版本可能更新不及时,推荐以下两种方式:
-
首选:Google Play 商店
 (图片来源网络,侵删)
(图片来源网络,侵删)- 在Google Play中搜索 “零度智控” 或 “ZEROTECH”,下载官方版本,这是最安全、更新最及时的方式。
-
备选:官网下载APK文件
- 访问 零度智控官方网站:
www.zerotech.com - 在网站的支持、下载或服务页面找到“Dobby”或“App下载”相关链接。
- 下载适用于您安卓手机版本的
.apk安装包文件。 - 下载后,请在手机设置中允许“安装来自未知来源的应用”,然后点击该文件进行安装。
- 访问 零度智控官方网站:
下载和使用的注意事项
-
认准官方,谨防山寨
- 务必认准开发者是 “零度智控(北京)科技有限公司”。
- 切勿从未经证实的第三方网站或论坛下载App,这些版本可能捆绑恶意软件、存在安全风险,或者功能不完整,导致无法正常连接无人机。
-
App版本与固件匹配
- Dobby无人机是一款较早的产品(发布于2025年),其App和固件都已停止更新。
- 如果您新安装的App无法连接无人机,请确保您的无人机App和飞控固件都已升级到 最新版本,您可以在App内的“设置”或“中找到固件升级选项。
-
手机兼容性问题
 (图片来源网络,侵删)
(图片来源网络,侵删)- 由于Dobby发布时间较早,它可能无法完美兼容最新款的安卓或iOS手机,常见问题包括:
- 无法通过Wi-Fi连接:Dobby通过手机Wi-Fi直连,不使用传统遥控器,请确保您的手机Wi-Fi功能正常。
- App闪退或无法打开:这通常是系统版本不兼容导致的,您可以尝试在安卓手机的“应用信息”中强制停止App,或清除缓存后重试。
- 图传信号差:请确保手机距离无人机不要太远,且周围Wi-Fi信号干扰较少。
- 由于Dobby发布时间较早,它可能无法完美兼容最新款的安卓或iOS手机,常见问题包括:
-
首次使用流程
- 下载并打开“零度智控”App。
- 打开Dobby无人机的电源,无人机会自动开机并发出提示音。
- 在手机上连接Dobby发出的Wi-Fi信号(名称通常为“Dobby_xxxxxx”)。
- 打开App,它会自动搜索并连接无人机,按照App内的提示进行后续操作(如校准指南针等)即可开始飞行。
如果您已经找不到Dobby无人机
如果您只是听说过Dobby,但不确定是否拥有它,
- Dobby早已停产:零度智控在2025年后就基本停止了Dobby的生产和销售。
- 官方服务可能已停止:相关的App服务器、固件更新和售后服务都已基本停止,如果遇到问题,可能很难获得官方支持。
| 项目 | |
|---|---|
| 正确App名称 | 零度智控 或 ZEROTECH |
| iOS下载 | App Store 搜索 “零度智控” |
| 安卓下载 | Google Play 搜索 “零度智控” 或 官网下载APK |
| 核心提示 | 务必从官方渠道下载,确保安全与功能正常。 |
| 注意事项 | 注意App与固件版本匹配,留意手机兼容性问题。 |
希望这些信息能帮助您顺利下载App并体验Dobby无人机!