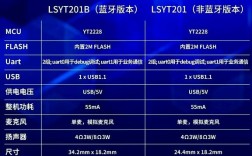
什么是OFDMA?(核心思想)
想象一下,你有一个非常宽的公路(无线频谱),但路上有很多汽车(用户数据),如果所有人都挤在一条车道上,很容易发生拥堵,效率极低。

OFDMA的解决方案是:把这条宽公路切成许多条并排的、互不干扰的窄车道(子载波),然后把不同的汽车分配到不同的车道上同时行驶。
技术术语解释:
- OFDM (Orthogonal Frequency Division Multiplexing):正交频分复用,这是“把宽路切成窄车道”的技术,它将高速的数据流分解成N个并行的、低速的子数据流,每个子数据流在一个独立的、正交的子载波(窄车道)上进行传输。“正交” 是关键,意味着这些子载波在频谱上是紧挨着的,但彼此之间不会产生干扰,就像不同颜色的光可以混合在一起但不会互相污染。
- Multiple Access (多址接入):多址接入,这是“如何分配车道给不同汽车”的技术,它允许多个用户同时共享这些子载波资源,调度器(交通警察)可以根据每个用户的信道质量、数据需求、位置等信息,动态地、灵活地将这些子载波“小块”(称为 Resource Element, RE)分配给不同的用户。
一句话总结:OFDMA = OFDM + 动态多址接入。 它是一种将频谱资源在“频率”和“用户”两个维度上进行精细分配的技术。
OFDMA是如何工作的?(工作原理)
OFDMA的物理信道传输过程可以分为发送端和接收端两个部分。

发送端(基站 eNodeB/gNB)的工作流程
假设基站需要同时为用户A、用户B和用户C传输数据。
步骤 1:资源块分配 基站有一个大的频谱资源池,它将其划分为一个个资源块,一个RB在频域上包含连续的多个子载波(例如12个),在时域上包含连续的几个OFDM符号(例如7个),这个“时间-频率”网格上的一个小格子就是一个资源元素。
步骤 2:调度与分配 基站的调度器会做出决策:
- 用户A:靠近基站,信号好,但只需要少量数据,调度器分配给他2个RB。
- 用户B:在小区边缘,信号差,需要更多的功率和资源来对抗衰落,调度器分配给他4个RB,并且可能分配在频谱的两端(频率分集)。
- 用户C:移动速度快,信道变化快,调度器为他分配的RB需要满足信道相干带宽。
步骤 3:数据调制与映射

- 每个用户的数据被独立地调制(如QPSK, 16QAM, 64QAM)成一系列的复数符号。
- 调度器将这些调制后的符号“映射”到分配给该用户的特定RE上,用户A的符号被放到时间-频率网格中属于他的那些格子里。
步骤 4:OFDM信号生成
- 在一个OFDM符号周期内,整个时间-频率网格上所有的RE都被填满了(有些是用户数据,有些可能是导频信号或空置)。
- 通过快速傅里叶逆变换,将这个频域上的网格数据转换成时域上的一个OFDM符号。
- 在每个OFDM符号之间加入循环前缀,用来对抗多径效应(防止前一符号的“尾巴”干扰到当前符号)。
步骤 5:上变频与发射 将生成的时域OFDM信号进行数模转换和上变频,然后通过天线发射出去。
接收端(手机 UE)的工作流程
手机接收到来自基站的混合信号后,需要进行相反的操作。
步骤 1:同步与下变频 手机首先进行时间/频率同步,然后将接收到的射频信号下变频到基带。
步骤 2:去除循环前缀 在每个OFDM符号的开始,去除循环前缀。
步骤 3:OFDM解调 对接收到的每个OFDM符号进行快速傅里叶变换,将其从时域转换回频域,重新得到那个时间-频率网格。
步骤 4:数据解调与解映射
- 根据基站的调度信息(手机已知),手机在网格中找到属于自己的那些RE。
- 从这些RE上提取出数据符号。
- 对这些符号进行解调(如QPSK解调),恢复出原始的比特流。
OFDMA的核心优势
-
高频谱效率
- 子载波正交:允许子载波之间紧密排列,几乎没有保护间隔,极大地利用了频谱资源。
- 灵活的带宽分配:系统可以根据业务需求,灵活使用1.4MHz, 3MHz, 5MHz, 10MHz, 20MHz甚至更大的带宽,非常适合从窄带到宽带的平滑演进。
-
强大的抗多径衰落能力
- 无线信号通过不同路径到达接收端,会造成时延扩展,导致符号间干扰。
- OFDM将一个宽带的频率选择性衰落信道,分解成了N个窄带的平坦衰落子信道,即使某些子信道因深衰落而性能很差,也只会影响承载在这些子信道上的少量数据,而不是整个数据块,这大大提高了系统的鲁棒性。
-
多用户分集与调度增益
- 这是OFDMA作为多址接入技术最强大的优势。
- 由于不同用户的位置、移动速度、环境不同,他们在同一时刻的信道质量千差万别。
- 调度器可以“见缝插针”,将资源分配给当前信道最好的用户,这就像一个餐厅,服务员总是优先服务点完菜且准备就绪的顾客,而不是让所有人都傻等,从而极大地提升了整个系统的吞吐量。
-
支持MIMO技术
OFDMA天然适合与MIMO(多输入多输出)技术结合,基站和终端都可以使用多根天线,在相同的时频资源上为不同用户或同一用户建立多个数据流,成倍地提升系统容量。
主要应用场景
- 4G LTE (Long-Term Evolution):OFDMA是LTE下行链路(基站到手机)的核心技术,上行链路则使用了与之类似的SC-FDMA(单载波FDMA),以降低手机的峰均比,从而节省电量。
- 5G NR (New Radio):OFDMA依然是5G NR的基石,在5G中,OFDMA被进一步演进,以支持更灵活的参数集(Numerology),可以适应不同的时延和子载波间隔需求,更好地满足eMBB(增强移动宽带)、URLLC(超高可靠低时延通信)和mMTC(海量机器类通信)三大场景。
OFDMA vs. CDMA (对比)
这是OFDMA能够取代3G时代CDMA技术的重要原因。
| 特性 | OFDMA (4G/5G) | CDMA (3G) |
|---|---|---|
| 多址方式 | 正交,用户在频率上分开 | 非正交,用户在码上分开 |
| 资源分配 | 动态、灵活,按需分配RB | 固定,每个用户始终占用整个频带 |
| 抗衰落 | 将宽带衰落分解为多个窄带平坦衰落,鲁棒性强 | 宽带频率选择性衰落,需要复杂的Rake接收机来合并多径 |
| 容量 | 软容量,系统容量取决于调度算法和用户分布 | 硬容量,用户数增加会相互干扰,导致所有用户性能下降(“小区呼吸”效应) |
| 调度 | 集中式调度(基站调度器),效率高 | 分布式,用户间通过功率控制等方式竞争,效率较低 |
| 实现复杂度 | 基站侧复杂度高(需要强大的调度和FFT/IFFT),手机侧相对简单 | 手机侧复杂度高(需要复杂的Rake接收机和功率控制),基站侧相对简单 |
挑战与缺点
- 对频率偏移敏感:由于子载波之间靠得非常近,收发双方的本地振荡器频率稍有偏差,或者多普勒效应,都会破坏子载波之间的正交性,产生载波间干扰。
- 高峰均比:OFDM信号是由多个子载波叠加而成,瞬时功率可能会远大于平均功率,即高PAPR,这对功率放大器的线性度要求很高,功放效率会降低,增加手机的成本和功耗,这也是为什么LTE上行采用SC-FDMA的原因。
- 需要精确的同步:系统对时间同步要求非常严格,循环前缀虽然提供了一定的保护,但同步误差仍会严重影响性能。
OFDMA 是一种革命性的物理层传输技术,它通过频域资源切片和动态调度相结合的方式,极大地提升了无线通信系统的频谱效率和用户体验,它成功地将OFDM的抗多径优势与多址接入的灵活性融为一体,成为支撑4G和5G高速、高效、大容量通信的基石,尽管存在一些挑战,但其带来的好处远远超过了其缺点,使其成为现代移动通信不可或缺的核心技术。