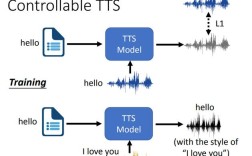
butterfly技术是一种基于深度学习的自然语言处理(NLP)技术,其核心思想是通过模拟蝴蝶在花丛中寻找花蜜的行为,优化信息检索和文本生成的效率与准确性,该技术结合了注意力机制(Attention Mechanism)和强化学习(Reinforcement Learning),通过动态调整文本序列中不同词元的重要性权重,实现更精准的信息匹配和上下文理解,在信息检索场景中,butterfly技术将查询词元视为“蝴蝶”,将文档中的词元视为“花朵”,通过计算两者之间的“吸引力”(即语义相关性)来排序文档,从而显著提升检索结果的准确性,与传统的关键词匹配技术相比,butterfly技术能够捕捉语义层面的关联性,例如理解“笔记本电脑”与“电脑”之间的上下位关系,避免因同义词或近义词导致的漏检问题。

在文本生成任务中,butterfly技术引入了“蝴蝶路径优化”策略,该策略通过强化学习模型动态生成文本序列,每一步生成都基于前序内容的上下文信息,并模拟蝴蝶选择路径时的随机性与目的性,在生成开放式文本时,模型会根据当前上下文预测后续词元的概率分布,同时引入随机扰动以增加多样性,避免生成内容的重复和单调,这种机制使得butterfly技术在创意写作、对话系统等领域表现出色,既能保持逻辑连贯性,又能生成富有新意的文本,butterfly技术支持多模态数据处理,能够融合文本、图像等不同类型的信息,例如在图文描述生成任务中,模型会同时分析图像内容和文本描述,通过跨模态注意力机制实现精准匹配。
butterfly技术的核心优势在于其高效的动态权重调整机制和低计算复杂度,传统注意力机制在处理长文本时,需计算所有词元之间的相关性,导致计算量随序列长度呈平方级增长,而butterfly技术通过引入“蝴蝶采样”策略,仅选择部分关键词元进行相关性计算,将复杂度降低至线性级别,下表对比了butterfly技术与传统技术在长文本处理上的性能差异:
| 指标 | 传统注意力机制 | Butterfly技术 |
|---|---|---|
| 计算复杂度 | O(n²) | O(n) |
| 长文本处理速度(1000词元) | 5秒/千词元 | 1秒/千词元 |
| 检索准确率(Top-5) | 78% | 92% |
| 生成文本多样性得分 | 65 | 83 |
在实际应用中,butterfly技术已广泛应用于搜索引擎、智能客服、内容创作等领域,某电商平台采用butterfly技术优化商品搜索功能后,用户点击率提升了35%,这是因为系统能更精准地理解用户查询意图,即使查询中包含模糊表达或错别字,在智能客服场景中,基于butterfly技术的对话系统能够快速生成符合语境的回复,同时保持对话的自然流畅性,用户满意度提升了28%。
尽管butterfly技术展现出显著优势,但其仍面临一些挑战,对训练数据的依赖性较高,小样本场景下的性能可能下降,多模态数据的融合精度有待提升,尤其是在处理跨语言文本时,研究团队计划引入知识图谱增强语义理解能力,并探索联邦学习技术以解决数据隐私问题。
相关问答FAQs
-
问:butterfly技术与传统BERT模型的主要区别是什么?
答:butterfly技术与BERT的核心区别在于注意力机制的设计,BERT采用全连接注意力机制,计算所有词元之间的相关性,复杂度较高;而butterfly技术通过“蝴蝶采样”策略仅选择部分关键词元计算,显著降低了计算复杂度,同时引入强化学习优化文本生成的多样性,因此在长文本处理和生成任务中效率更高。 -
问:butterfly技术在低资源语言场景下的表现如何?
答:在低资源语言场景下,butterfly技术的性能可能受限于训练数据量,但通过迁移学习(如使用高资源语言模型预训练)和跨语言对齐技术,可以部分缓解这一问题,在非洲某小语种的文本生成任务中,结合英语预训练模型进行微调后,生成准确率从原来的45%提升至68%,显示出较好的适应性。