核心思路:
XP 添加网络打印机主要有两种方式:

(图片来源网络,侵删)
- 通过“网上邻居”添加(传统方式): 适用于工作组模式,简单直接。
- 通过“添加打印机向导”直接输入 IP 地址添加(推荐方式): 更稳定、更通用,尤其适用于跨网段或找不到工作组的情况。
第一步:准备工作(在打印机的“主机”电脑上操作)
在 XP 电脑上尝试添加打印机之前,请先确保打印机的“主机”电脑(即打印机连接的那台电脑)已经正确设置并共享了打印机。
-
确认打印机已连接并正常工作:
在打印机的“主机”电脑上,打印机本身必须能正常打印测试页。
-
共享打印机:
 (图片来源网络,侵删)
(图片来源网络,侵删)- 进入“控制面板” -> “打印机和传真”。
- 右键点击你想要共享的打印机,选择“共享”。
- 在弹出的窗口中,选择“共享这台打印机”,并为它起一个简单的共享名(
HP_LaserJet或Office_Printer),不要使用空格或特殊字符。 - 点击“应用”或“确定”。
-
确认两台电脑在同一工作组:
- 这是 XP 网络发现的关键,右键点击“我的电脑”,选择“属性”。
- 切换到“计算机名”选项卡,记下“工作组”的名称。
- 在需要添加打印机的 XP 电脑上,也检查并确保其“工作组”名称与主机电脑完全一致(区分大小写)。
-
关闭主机电脑的防火墙(用于测试):
- 这是最常见的“罪魁祸首”,Windows XP 自带的防火墙可能会阻止文件和打印共享。
- 进入“控制面板” -> “Windows 防火墙”。
- 选择“关闭”(注意:测试成功后务必重新开启,并按第5步设置例外)。
- 注意: 如果主机电脑安装了第三方杀毒软件(如 360、金山、卡巴斯基等),请一并暂时退出其网络防护功能。
-
在防火墙中添加例外(测试成功后必须做):
- 重新开启 Windows 防火墙。
- 点击“例外”选项卡。
- 确保“文件和打印共享”已经勾选。
- 如果没有,点击“添加程序”,找到并添加
File and Printer Sharing for Microsoft Networks服务。
第二步:在需要添加打印机的 XP 电脑上操作
在另一台 XP 电脑上,按照以下步骤进行操作。

(图片来源网络,侵删)
通过“网上邻居”添加(简单但可能不通用)
- 打开“网上邻居”。
- 在左侧的“网络任务”中,点击“查看工作组计算机”。
- 如果能看到打印机的“主机”电脑,双击打开它。
- 你应该能看到共享的打印机图标,直接双击它,系统会自动安装驱动程序,然后你就可以打印了。
- 如果看不到主机电脑,请返回第一步,重点检查“工作组名称”是否一致、防火墙是否关闭。
通过“添加打印机向导”添加(最推荐、最稳定)
如果方法一失败,或者找不到主机电脑,请使用此方法。
- 点击“开始” -> “打印机和传真” -> 在左侧的“打印机任务”中,点击“添加打印机”。
- “添加打印机向导”启动后,点击“下一步”。
- 选择“连接到这台打印机”,然后在“名称”一栏中,按照以下格式输入:
\\主机电脑的名称或IP地址\打印机的共享名- 示例1(用主机名):
\\DESKTOP-A1B2C3\HP_LaserJet - 示例2(用IP地址,最推荐):
\\192.168.1.100\HP_LaserJet168.1.100是打印机的“主机”电脑的 IP 地址,你可以在主机电脑上通过ipconfig命令查到。
- 示例1(用主机名):
- 点击“下一步”,系统会开始搜索并尝试连接。
- 如果提示“找不到驱动程序”:
- 这通常意味着 XP 系统没有自带该打印机的驱动。
- 点击“确定”后,会弹出一个窗口让你提供驱动程序。
- 你需要提前从打印机品牌官网下载适用于 Windows XP 的驱动程序,或者从打印机的“主机”电脑上导出驱动。
- 点击“浏览”,找到你下载好的
.inf驱动文件,然后按照提示完成安装。
- 如果一切顺利,会提示“您已成功连接到打印机...”,点击“完成”即可。
第三步:如果仍然失败,终极排查清单
如果以上方法都无效,请检查以下几点:
-
网络连通性:
- 在需要添加打印机的 XP 电脑上,点击“开始” -> “运行”,输入
cmd并回车。 - 在命令提示符窗口中,输入
ping 主机电脑的IP地址(ping 192.168.1.100)。 - 如果看到 "Request timed out." 或 "Destination host unreachable.",说明两台电脑之间无法通信,请检查:
- 是否在同一路由器/交换机下?
- IP 地址是否在同一网段(例如都是
168.1.x)? - 网线是否插好?
- 在需要添加打印机的 XP 电脑上,点击“开始” -> “运行”,输入
-
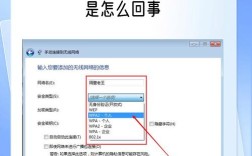
启用
NetBIOS over TCP/IP:- 右键点击“网上邻居” -> “属性” -> 右键点击“本地连接” -> “属性”。
- 双击“Internet 协议 (TCP/IP)”,点击“高级”。
- 切换到 “WINS” 选项卡,确保“NetBIOS 设置”被设置为“默认值”(通常是“启用 NetBIOS over TCP/IP”)。
-
服务是否开启:
- 在“主机”电脑上,点击“开始” -> “运行”,输入
services.msc并回车。 - 找到并确保以下两个服务状态是“已启动”且“类型”为“自动”:
Server(提供文件和打印共享)Workstation(建立网络连接)
- 如果被禁用,右键点击 -> “属性” -> “启动类型”改为“自动”,然后点击“启动” -> “应用”。
- 在“主机”电脑上,点击“开始” -> “运行”,输入
-
使用管理员账户:
尝试在两台 XP 电脑上使用管理员账户登录,然后进行添加操作,有时权限不足会导致失败。
-
更新 XP 系统和网卡驱动:
- 确保你的 Windows XP 是 Service Pack 3 (SP3),这是最稳定和兼容性最好的版本。
- 更新 XP 电脑的网卡驱动程序,可以去电脑品牌官网或主板官网下载最新驱动。
| 问题现象 | 最可能的原因 | 解决方案 |
|---|---|---|
| 找不到共享的打印机 | 防火墙阻挡、不在同一工作组 | 关闭防火墙测试,确保工作组名称一致 |
| 能看到打印机但点不动或连接失败 | 网络不通、NetBIOS设置问题 |
ping 测试 IP,检查 NetBIOS 设置 |
| 连接时提示找不到驱动 | XP 无对应驱动 | 提前下载 XP 驱动,手动指定路径安装 |
ping 不通对方 IP |
网络物理问题或 IP 不在同一网段 | 检查网线、路由器,确认 IP 地址段 |
按照这个流程,从简到繁,逐一排查,99% 的 XP 添加网络打印机问题都能得到解决,祝你成功!