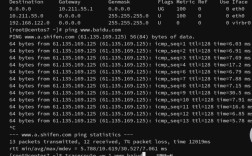
通过“设置”应用(最常用)
这是进行所有网络设置的主要入口。

(图片来源网络,侵删)
-
打开“设置”应用
- 在手机桌面上找到齿轮形状的 “设置” 图标,点击进入。
-
进入“移动网络”或“SIM卡与移动数据”
- 向下滑动设置菜单,找到 “移动网络” (Mobile network) 或 “SIM卡与移动数据” (SIM card & mobile data) 这一项,点击进入。
- 注意:不同MIUI版本,这里的名称可能略有差异,但功能是一样的。
- 向下滑动设置菜单,找到 “移动网络” (Mobile network) 或 “SIM卡与移动数据” (SIM card & mobile data) 这一项,点击进入。
-
您可以进行所有核心的网络设置:
- 首选网络类型:这是最重要的设置之一,用于选择4G/3G/2G的网络模式。
- 您可以选择“4G/3G/2G 自动选择”,让手机自动连接最佳网络。
- 也可以选择仅使用“4G”或“3G”等,以节省流量或在信号不好的时候稳定网络。
- 接入点名称:也就是我们常说的 APN,如果您无法上网,可能需要在这里检查或配置APN。
- 个人热点:开启手机热点,让其他设备(如电脑、平板)通过您的手机网络上网。
- VoLTE高清通话:如果您的运营商和套餐支持,开启此项可以在打电话时同时使用4G网络上网,通话质量也更好。
- 数据漫游:在出国时使用移动数据需要开启此功能。
- SIM卡信息:可以查看SIM卡状态、设置PIN码锁等。
- 首选网络类型:这是最重要的设置之一,用于选择4G/3G/2G的网络模式。
辅助方法:通过“控制中心”进行快速开关
如果您只是想快速打开或关闭移动数据、Wi-Fi、蓝牙等,可以使用控制中心,这里更快捷。

(图片来源网络,侵删)
-
从屏幕顶部向下滑动
- 在主屏幕或任何应用界面,从屏幕最顶端向下滑动,即可调出 控制中心。
-
找到网络开关
- 在控制中心,您会看到各种快捷开关,包括:
- 移动数据:可以一键开关移动数据流量。
- Wi-Fi:可以快速开关Wi-Fi。
- 蓝牙:开关蓝牙。
- 个人热点:开关热点。
- 飞行模式:开启后,所有无线网络(Wi-Fi, 移动数据, 蓝牙)都会被关闭。
- 在控制中心,您会看到各种快捷开关,包括:
总结一下
| 您要进行的操作 | 设置路径 | 快捷方式 |
|---|---|---|
| 设置4G/3G网络模式、APN、VoLTE等 | 设置 > 移动网络 / SIM卡与移动数据 | 无 |
| 快速开关Wi-Fi、移动数据 | 设置 > WLAN / 移动网络 | 控制中心 的开关 |
| 开启/关闭个人热点 | 设置 > 移动网络 > 个人热点 | 控制中心 的开关 |
| 连接新的Wi-Fi | 设置 > WLAN | 控制中心 长按Wi-Fi图标进入详细列表 |
- 需要详细配置:去 “设置” 里的 “移动网络”。
- 只需要快速开关:从屏幕顶部下滑,用 “控制中心”。
希望这个详细的解答能帮助您轻松找到小米4X的网络设置!

(图片来源网络,侵删)