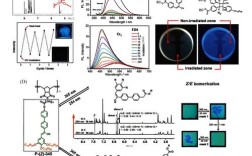
Palantir技术作为大数据分析和复杂系统整合领域的代表性解决方案,其核心能力源于对海量异构数据的深度处理、实时关联及动态决策支持,该技术体系以模块化架构为基础,通过数据融合引擎、分布式计算框架及可视化交互平台三大支柱,构建了从数据采集到决策输出的完整闭环,在金融风控、国防安全、医疗健康等高复杂度场景中展现出独特价值。

技术架构与核心组件
Palantir技术采用分层解耦设计,底层通过FUSE(Filesystem in Userspace)协议实现跨源数据接入,支持结构化数据库、非结构化文档及物联网流数据的实时采集,中间层的Grappling Hook组件负责数据标准化处理,将原始信息转化为统一的知识图谱模型,其实体关系识别引擎可基于自然语言处理技术自动构建关联网络,上层应用平台分为Foundry和Gotham两大产品线:Foundry专注于企业级数据分析,提供可拖拽的数据建模工具;Gotham则面向国家安全等高敏感场景,采用零信任架构实现数据隔离与权限管控。
在计算能力方面,Palantir自研的Presto SQL引擎支持千亿级数据的亚秒级查询,其列式存储格式结合向量化执行技术,较传统数据库性能提升30倍以上,通过动态资源调度算法,系统可根据任务负载自动分配计算节点,在处理时空数据时采用GeoMesa索引技术,实现百万级地理坐标的毫秒级检索。
数据融合与知识发现机制
该技术的核心突破在于多模态数据的语义融合能力,通过构建三层知识图谱架构:原始数据层存储传感器日志、交易记录等原始信息;概念层利用BERT模型进行实体消歧与关系抽取;应用层则基于强化学习实现动态推理,例如在反洗钱场景中,系统可通过交易链路分析自动识别跨账户资金拆分行为。
下表展示了Palantir在不同数据类型处理中的技术优势: | 数据类型 | 处理技术 | 典型应用场景 | 处理时效性 | |----------|----------|--------------|------------| | 结构化数据 | 分布式SQL引擎 | 银行交易审计 | 实时 | | 文本数据 | NLP实体识别 | 情报报告分析 | 分钟级 | | 时序数据 | 流处理窗口计算 | 工业设备监控 | 毫秒级 | | 空间数据 | GeoMesa索引 | 应急资源调度 | 秒级 |

动态决策与场景适配能力
Palantir技术通过内置的“What If”模拟引擎,支持用户在虚拟环境中验证决策方案,在疫情防控场景中,系统可基于人口流动数据预测病毒传播路径,并模拟不同封控措施的经济影响,其自适应学习模块能够持续优化模型参数,例如在供应链风险管理中,通过分析历史中断事件自动调整风险预警阈值。
该技术的可视化平台采用Loom架构,支持将复杂数据关系转化为可交互的动态图谱,用户可通过自然语言查询生成定制化仪表盘,例如在智能制造场景中,设备经理可通过语音指令调取产线良品率与原料质量的关联分析报告。
安全与合规特性
在数据安全方面,Palantir采用联邦学习技术实现数据可用不可见,原始数据始终保留在本地节点,仅交换模型参数,其隐私保护模块支持差分隐私算法,可在数据发布时添加经过校准的噪声,防止个体信息泄露,系统通过ISO 27001和SOC 2 Type II认证,所有操作日志采用区块链技术存证,确保审计可追溯。
相关问答FAQs
Q1:Palantir技术与传统BI工具的核心区别是什么?
A1:传统BI工具主要处理结构化数据且依赖预设报表,而Palantir技术能够融合多源异构数据,通过知识图谱实现动态关联分析,支持实时决策调整,其区别主要体现在三个维度:数据范围上支持非结构化数据占比超60%;分析模式上从静态报表转向动态模拟;响应速度上实现亚秒级复杂查询,适合处理高不确定性场景。
Q2:Palantir系统如何保障大规模部署时的性能稳定性?
A2:系统采用多层次的性能保障机制:在数据层通过分片存储和冷热数据分离技术降低I/O压力;计算层基于Kubernetes实现容器化弹性扩容,可支持万级节点并发;应用层设置智能流量调度系统,自动识别并隔离异常查询,通过在金融客户的压力测试显示,系统在10PB数据量下仍保持99.9%的查询成功率,平均响应延迟控制在200ms以内。