Hadoop技术架构图是理解Hadoop生态系统核心组件及其交互关系的关键视觉工具,其设计以HDFS(分布式文件系统)和MapReduce(分布式计算框架)为基础,逐步扩展至YARN(资源管理框架)及多种周边组件,形成了一套完整的分布式存储与计算解决方案,以下从核心组件、数据流向、扩展模块三个维度,详细解析Hadoop技术架构的构成逻辑。

核心组件:HDFS与MapReduce的协同设计
Hadoop技术架构的底层以HDFS和MapReduce为双支柱,二者通过数据流紧密耦合,构成“存储-计算”的基础闭环。
HDFS(分布式文件系统)采用主从架构(Master-Slave),由NameNode(主节点)、DataNode(从节点)和Secondary NameNode(辅助节点)组成,NameNode作为“元数据管理中心”,负责存储文件系统的命名空间(如文件目录结构、权限信息)和数据块(Block)的映射关系(默认块大小128MB或256MB),同时协调客户端与DataNode间的数据交互;DataNode则是“数据存储节点”,实际存储文件数据块,并通过心跳机制向NameNode汇报状态(如存储容量、节点健康度);Secondary NameNode并非NameNode的备份,而是定期合并NameNode的 edits.log 与 fsimage,生成新的元数据镜像,减轻NameNode的负载,HDFS的高容错性体现在:每个数据块默认存储3个副本(可配置),分布在不同机架的DataNode上,确保单节点故障时不丢失数据;数据写入时采用“流水线复制”机制,由客户端按顺序将数据块推送给多个DataNode,提升写入效率。
MapReduce(分布式计算框架)是Hadoop的经典计算模型,分为Map(映射)和Reduce(规约)两个阶段,适用于离线批处理场景,Map阶段接收输入数据(通常来自HDFS文件),通过用户自定义的Map函数对数据进行拆分和初步处理(如过滤、格式转换),输出键值对(Key-Value);Reduce阶段接收Map阶段的输出结果,按Key进行分组聚合,通过用户自定义的Reduce函数生成最终结果(如统计、汇总),MapReduce的执行流程由JobTracker(任务跟踪器,Hadoop 1.x中的组件)或ResourceManager(资源管理器,Hadoop 2.x中的组件)协调:JobTracker/ResourceManager接收客户端提交的作业(Job),将其拆分为多个Task(Map Task和Reduce Task),并分配给TaskTracker(任务执行器)或NodeManager(节点管理器);TaskTracker/NodeManager在本地执行Task,并通过心跳机制向JobTracker/ResourceManager汇报进度;作业完成后,结果输出至HDFS。
不同Hadoop版本的核心组件对比
| 组件 | Hadoop 1.x角色 | Hadoop 2.x及之后角色 | 核心改进 |
|---|---|---|---|
| 资源管理 | JobTracker(单点故障) | ResourceManager(高可用) | 拆分资源管理(ResourceManager)与任务调度(ApplicationMaster),支持HA |
| 任务执行 | TaskTracker | NodeManager | 轻量化节点管理,支持多容器并发执行 |
| 作业调度 | 内置调度器 | 可插拔调度器(如Fair Scheduler) | 支持多租户资源隔离、优先级调度 |
| 元数据管理 | NameNode(单点故障) | NameNode(HA+QJM) | 通过JournalNode实现元数据实时同步,避免SPOF(单点故障) |
资源调度层:YARN的引入与架构演进
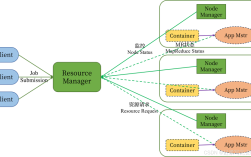
Hadoop 2.x引入YARN(Yet Another Resource Negotiator),重构了资源管理与任务调度的分离架构,使Hadoop从单一的批处理平台升级为支持多计算框架(如Spark、Flink、Hive)的统一资源调度中心,YARN架构由全局ResourceManager(RM)、每个应用程序的ApplicationMaster(AM)和NodeManager(NM)组成。

ResourceManager是集群资源的“总管家”,负责全局资源分配(如CPU、内存),并接收客户端提交的应用(Application),为每个应用分配ApplicationMaster;ApplicationMaster是应用的“调度器”,与RM协商资源后,向NM申请容器(Container,资源抽象),监控应用内Task的执行进度,并向RM汇报状态;NodeManager是节点的“资源代理”,负责监控本节点资源(如CPU使用率、内存占用),管理容器的生命周期,并向RM汇报心跳信息,YARN的调度流程为:客户端向RM提交Application,RM为该Application分配AM并启动AM;AM向RM注册后,根据应用需求向RM申请资源(如Map Task需要2GB内存、1个vCPU);RM返回可用资源列表(包含NM的Container信息),AM与NM协商启动Task;Task执行完成后,AM向RM注销,释放资源,YARN的插拔式调度器(如Capacity Scheduler支持多队列资源分配、Fair Scheduler实现公平共享)进一步提升了集群资源利用率,解决了Hadoop 1.x中JobTracker单点故障和资源调度僵化的问题。
扩展模块:生态系统的丰富与完善
基于HDFS和YARN的底层能力,Hadoop生态系统衍生出多种组件,覆盖数据采集、存储、分析、可视化全流程。
数据采集层:Flume(日志采集工具)通过Source(数据源,如文件、Kafka)、Channel(数据缓冲区,如Memory、File)、Sink(数据目的地,如HDFS、HBase)的管道模型,实时采集海量日志数据;Sqoop(数据迁移工具)支持关系型数据库(如MySQL、Oracle)与HDFS/Hive间的数据双向传输,通过MapReduce实现并行导入导出,提升迁移效率。
数据存储层:HBase(分布式列式数据库)构建于HDFS之上,支持海量结构化数据的实时随机读写,适用于存储稀疏数据(如用户画像、时序数据),通过RegionServer(分片服务器)将表按RowKey水平拆分为多个Region,分布在不同节点上;Hive(数据仓库工具)提供类SQL的查询语言(HQL),将SQL语句转换为MapReduce或Tez(DAG计算框架)任务,实现HDFS中数据的结构化查询,适合离线数据分析场景。

数据分析层:Spark(内存计算框架)基于YARN运行,利用RDD(弹性分布式数据集)实现数据内存缓存,迭代计算性能比MapReduce高10-100倍,支持批处理(Spark SQL)、流处理(Spark Streaming)、机器学习(MLlib)、图计算(GraphX)等多种场景;Flink(流批一体框架)以事件驱动为核心,支持毫秒级流处理和批量数据处理,通过Checkpoint机制实现Exactly-Once语义,适用于实时风控、实时推荐等低延迟场景。
数据可视化层:Superset(开源BI工具)通过连接Hive、HBase等数据源,提供丰富的图表组件(如折线图、热力图)和交互式仪表盘,支持自定义SQL查询;Zeppelin(Web笔记本)支持多语言(Scala、Python、SQL)数据分析,集成了数据可视化、任务调度等功能,适合数据科学家进行探索性分析。
数据流向:从采集到输出的完整链路
以“网站日志分析”场景为例,Hadoop技术架构的数据流可概括为:
- 数据采集:Flume Source采集Web服务器日志(如Nginx访问日志),通过Memory Channel缓冲后,Sink将数据实时写入HDFS的
/logs/2025-10-01/目录; - 数据存储:日志数据以文件形式存储在HDFS中,按日期分片(如
access_20251001_0001.log),每个文件块(Block)存储3个副本,分布在不同DataNode上; - 数据清洗:通过Hive创建外部表关联HDFS日志数据,使用HQL清洗数据(如过滤无效请求、解析User-Agent);
- 数据分析:清洗后的数据导入Hive分区表,使用Spark SQL统计UV(独立访客)、PV(页面浏览量),或通过MapReduce计算用户访问时长Top10;
- 结果输出:分析结果存储在HBase中,Superset连接HBase生成实时仪表盘,或通过Sqoop导出到MySQL供业务系统调用。
相关问答FAQs
Q1:HDFS与传统文件系统(如EXT4)的核心区别是什么?
A:HDFS与传统文件系统的核心区别在于架构设计目标与实现机制:
- 存储架构:传统文件系统为集中式存储(单节点磁盘),HDFS为分布式存储(多节点数据块),通过副本机制实现高容错(默认3副本);
- 访问模式:传统文件系统支持低延迟随机读写(如数据库文件),HDFS针对高吞吐量顺序读写优化(如大文件流式访问),不适合低延迟场景;
- 元数据管理:传统文件系统元数据存储在本地 inode 中,HDFS元数据由NameNode集中管理(内存存储),支持PB级文件目录结构;
- 适用场景:传统文件系统适用于通用计算场景,HDFS适用于海量数据(TB/PB级)的离线存储与批处理,如日志、视频、科学数据。
Q2:YARN的Capacity Scheduler与Fair Scheduler如何选择?
A:Capacity Scheduler(容量调度器)和Fair Scheduler(公平调度器)是YARN的两种主流调度器,选择需结合集群使用场景:
- Capacity Scheduler:适合多租户企业级集群,通过划分队列(如“生产队列”“测试队列”)分配固定资源容量,支持队列间资源抢占(高优先级队列可抢占低优先级队列资源),确保核心业务(如生产作业)资源稳定,适用于资源隔离要求高、业务优先级分明的场景;
- Fair Scheduler:适合多团队共享集群,通过“公平”策略动态分配资源(按权重或时间片),确保每个作业长期获得公平资源份额,支持任务优先级和资源保证(如设置用户最小资源),适用于探索性分析、实验性任务较多的场景(如高校、科研机构)。
实际应用中,企业可通过配置队列参数(如容量、权重、权限)混合使用两种调度器,例如生产队列用Capacity Scheduler保证资源,测试队列用Fair Scheduler共享剩余资源。