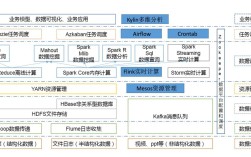
Discuz作为国内广泛使用的社区论坛系统,其数据存储和管理效率直接影响论坛的性能和用户体验,随着用户量和数据量的激增,单表存储数据的方式逐渐成为性能瓶颈,此时分表技术便成为提升系统性能的重要手段,分表技术通过将大表拆分为多个小表,分散数据存储压力,优化查询效率,是应对大数据量场景的有效解决方案。

Discuz的分表技术主要基于MySQL数据库,其核心思想是将一张大表按照某种规则拆分成多张结构相同的子表,这些子表可以分布在同一数据库服务器上,也可以分布在不同服务器上,从而实现数据的分布式存储,常见的分表方式包括垂直分表和水平分表,两者适用场景和实现方式存在显著差异。
垂直分表是指按照业务逻辑将表中的字段拆分到多张表中,每个子表包含部分字段,这种方式主要针对表中字段较多、字段类型差异大的情况,Discuz的用户表中可能包含用户基本信息(如用户名、密码、邮箱)、用户扩展信息(如积分、等级、签名)等大文本字段,通过垂直分表,可以将基本信息和扩展信息分别存储到不同的表中,减少单表的数据量,提高查询效率,垂直分表的优点在于拆分简单,符合业务逻辑,能够减少I/O次数;缺点是可能导致关联查询增多,需要多表JOIN操作,对数据库性能产生一定影响,在Discuz中,垂直分表通常用于用户表、帖子表等字段较多的核心表,但需谨慎处理表关联关系,避免过度拆分导致查询复杂化。
水平分表是指按照某种规则将表中的数据行拆分到多张子表中,每个子表包含相同的字段结构,但存储不同的数据范围,水平分表是应对数据量激增的主要手段,尤其适用于数据行数巨大的表,如日志表、帖子表等,水平分表的关键在于选择合适的分片键(Shard Key),分片键的选择直接影响数据分布的均匀性和查询效率,常见的分片规则包括取模、哈希、范围分片等,以用户ID为分片键,通过取模运算将用户数据分配到不同的子表中(如user_0、user_1……user_n),或按照时间范围将帖子表拆分为按年或按月的子表,水平分表的优点在于可以有效分散数据压力,提高单表查询效率,适合大数据量场景;缺点是跨表查询复杂,需要额外的路由逻辑,且分片键选择不当可能导致数据倾斜,在Discuz中,水平分表常用于帖子表(posts)、附件表(attachments)等,通过插件或二次实现分表逻辑,确保数据的读写操作能够正确路由到对应的子表。
Discuz分表技术的实现需要综合考虑数据库架构、业务需求和性能优化目标,在具体实践中,通常需要结合数据库中间件(如ShardingSphere、MyCat)或自定义路由逻辑来实现分表功能,以帖子表的水平分表为例,假设按照发帖时间进行分片,可以将2025年的帖子数据存储在posts_2025表中,2025年的数据存储在posts_2025表中,这样在查询特定时间段的帖子时,可以直接定位到对应的子表,避免全表扫描,Discuz的分表还需要考虑事务一致性、跨表统计等问题,例如在用户积分变更时,可能需要同时更新多个子表的数据,此时需要确保事务的原子性。

分表技术的应用并非没有代价,它增加了系统架构的复杂性,需要额外的开发和维护成本,分表后的数据管理(如备份、恢复、迁移)变得更加复杂,跨表查询需要编写复杂的SQL语句或借助中间件处理,分表后可能面临跨分片事务的问题,尤其是在需要保证多个子表数据一致性的场景下,需要采用分布式事务解决方案(如两阶段提交、TCC模式),在决定是否采用分表技术时,需要充分评估当前数据量、增长趋势以及业务需求,避免过早优化或过度设计。
为了更直观地展示分表技术的应用效果,以下以Discuz帖子表为例,对比分表前后的性能差异:
| 指标 | 分表前(单表存储1000万条数据) | 分表后(按年拆分为10个子表,每表100万条数据) |
|---|---|---|
| 单次查询耗时 | 平均500ms(全表扫描) | 平均50ms(定位到具体子表) |
| 写入性能 | 每秒约100次插入 | 每秒约1000次插入(分散到不同子表) |
| 存储空间 | 单表占用50GB | 每个子表占用5GB,总存储空间相同 |
| 备份时间 | 约2小时 | 约20分钟(可并行备份子表) |
从表格可以看出,分表技术显著提升了查询和写入性能,尤其是在数据量较大的场景下,优势更为明显,分表后的系统维护复杂度有所增加,需要专业的运维团队支持。
在实际应用中,Discuz论坛管理员和开发者需要根据论坛的发展阶段选择合适的分表策略,对于初创期或中小型论坛,单表存储可能已足够满足需求;当论坛进入快速发展期,数据量激增导致性能下降时,可以考虑引入分表技术,分表的实施建议遵循“先垂直后水平”的原则,即优先对字段较多的表进行垂直拆分,再对数据量大的表进行水平拆分,分片键的选择应尽量遵循“热点分散”原则,避免某些子表的数据量远大于其他子表,导致新的性能瓶颈。
相关问答FAQs:
问题1:Discuz分表后如何实现跨子表的查询?
解答:跨子表查询需要借助数据库中间件或自定义路由逻辑,使用ShardingSphere等中间件可以配置分片规则,中间件会根据分片键自动路由到对应的子表执行查询,对于需要查询多个子表的场景,可以使用UNION ALL将结果合并,但需注意性能影响,在分表设计时应尽量避免频繁的跨子表查询,尽量通过业务逻辑优化将查询范围限定在单个子表内。
问题2:分表技术是否会影响Discuz插件的功能?
解答:分表技术可能会影响依赖单表查询的插件功能,某些插件需要统计全表数据(如总帖子数、总用户数),分表后需要聚合多个子表的结果,可能导致查询效率下降,解决方法包括:① 使用缓存技术(如Redis)存储统计结果;② 修改插件逻辑,使其支持分表查询;③ 在分表时保留统计字段,通过定时任务更新统计值,在实施分表前,需评估插件兼容性,必要时对插件进行二次开发。