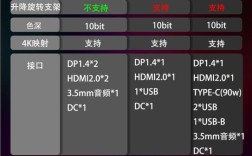
"Arrisky" 并不是一个主流的、由大型制造商(如 Samsung, LG, AUO, BOE 等)生产的官方面板型号,它更像是一个在特定市场(如中国国内的显示器、广告机、工控等领域)或特定渠道中使用的**品牌名或系列名**。

(图片来源网络,侵删)
其技术参数没有一个统一的、官方的公开标准,参数会根据具体的产品型号、尺寸、定位(是消费级显示器还是专业级广告机)而有很大差异。
我们可以根据市场上常见的被称为 "Arrisky Panel" 的产品,总结出一些典型的、常见的技术参数范围,并解释这些参数的含义,这可以帮助您了解这类面板通常具备什么样的性能。
Arrisky Panel 典型技术参数概览
以下参数列出了不同规格下可能出现的数值范围,具体请以您所查询的具体产品规格书为准。
| 参数类别 | 参数项 | 典型范围 (消费级/办公) | 典型范围 (专业/广告机/工业) | 参数解释 |
|---|---|---|---|---|
| 基本规格 | 尺寸 | 5", 24", 27", 32" | 1", 15.6", 21.5", 27", 32", 43", 49", 55" (尺寸选择非常灵活) | 指屏幕对角线的长度,单位为英寸,工业/广告机尺寸更多样化。 |
| 面板类型 | IPS (主流) VA (部分) |
IPS (主流,色彩和视角好) VA (高对比度) TN (少部分,响应快但色彩差) |
IPS: 色彩好、可视角度大,是目前主流。 VA: 对比度高,黑色纯净,但响应速度和视角略逊于IPS。 TN: 响应最快,但色彩和视角最差,多用于电竞或对成本敏感的领域。 |
|
| 分辨率 | FHD (1920x1080) (主流) QHD (2560x1440) (部分高端) |
FHD (1920x1080) (主流) 4K UHD (3840x2160) (高端广告机) |
屏幕的像素数量,分辨率越高,画面越精细,FHD 是目前最普及的标准。 | |
| 显示性能 | 亮度 | 250 - 300 cd/m² | 300 - 700 cd/m² (甚至更高) | cd/m² 是亮度的单位,亮度越高,在明亮环境下越清晰。工业/广告机面板亮度远高于普通显示器,以应对强光环境。 |
| 对比度 | 1000:1 (IPS/VA) 3000:1 (部分VA) |
1000:1 (IPS) 3000:1 (VA) 5000:1:1 (高对比度VA) |
黑色与白色的亮度比值,对比度越高,黑色越纯净,层次感越好。 | |
| 色彩表现 | 72% NTSC / 99% sRGB (主流) 90%+ DCI-P3 (部分高端) |
72% NTSC / 99% sRGB (主流) 90%+ DCI-P3 (高端广告机/设计) |
指面板能够显示的色彩范围,数值越高,色彩越丰富。sRGB 是通用标准,DCI-P3 是电影/广色域标准。 | |
| 响应时间 | 5ms (GTG, 典型值) 1ms (GTG, 部分游戏型号) |
5ms - 8ms (GTG) | 指像素从一种颜色切换到另一种颜色所需的时间,数值越低,拖影越少,动态画面越清晰,工业应用对此要求不高。 | |
| 可视角度 | 178°/178° (IPS标准) 170°/160° (VA标准) |
178°/178° (IPS标准) | 指从不同角度观看屏幕时,画面不发生色彩和亮度偏移的最大角度,IPS面板在这方面优势明显。 | |
| 接口与电源 | 视频输入 | HDMI (主流) DisplayPort (部分高端) VGA (老旧型号) |
HDMI + VGA (非常常见) DisplayPort LVDS/eDP (用于内置主板) |
连接信号源的接口,工业和广告机产品为了兼容性,通常会同时保留HDMI和VGA。 |
| 触摸功能 | 可选 | 非常普遍 (电容式/电阻式) | 很多工业和广告机面板会集成触摸功能,方便人机交互。 | |
| 工作温度 | N/A (室内使用) | -20°C ~ 70°C (宽温) | 工业级面板的重要指标,指能正常工作的环境温度范围。 | |
| 存储温度 | N/A | -30°C ~ 80°C | 指在不通电情况下可以存放的温度范围。 | |
| 电源 | 内置电源适配器 | 外置电源适配器 或 内置电源 | 工业和广告机为了节省空间和便于安装,常使用外置“电源砖”。 | |
| 安装与结构 | 安装方式 | VESA壁挂 (75x75mm, 100x100mm) | VESA壁挂 (多种标准) 开放式/裸板 (供客户集成到自己的设备中) |
裸板 是工业面板的一大特点,只提供屏幕和接口,不包含外壳,方便客户进行二次开发。 |
如何获取您需要的具体型号参数?
由于 "Arrisky" 是一个系列品牌,最准确的方法是:

(图片来源网络,侵删)
- 查找产品型号:找到您感兴趣的产品的完整型号,这通常在产品标签、包装盒或产品页面上。
- 搜索规格书:使用完整型号加上 "datasheet" 或 "specification" 或 "规格书" 等关键词进行搜索。
- 搜索
Arrisky ASH-27F1H Datasheet。
- 搜索
- 联系供应商:如果您是从某个供应商处采购,直接向他们索要该型号的官方规格书是最可靠的方式。
"Arrisky Panel" 是一个覆盖面广、应用多样的产品线,其技术参数的核心特点是:
- 灵活性高:尺寸、分辨率、亮度、接口等组合非常丰富。
- 应用导向:参数设计完全服务于其应用场景,广告机面板追求高亮度,工业面板追求宽温和可靠性,而办公/消费级面板则更侧重色彩和性价比。
- 信息分散:没有统一官网,参数需要通过具体型号和供应商来获取。
希望这份详细的参数解释和范围能对您有所帮助!

(图片来源网络,侵删)