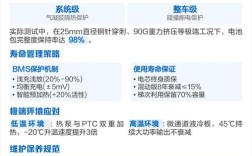
NVIDIA NVLink 是一种高速、高带宽的互连技术,主要用于在多个 NVIDIA GPU(图形处理器)之间建立直接、快速的通信桥梁。

您可以把它想象成 GPU 之间的“超级高速公路”,而传统的多GPU方案(如 SLI)则像是“普通国道”,这条“超级高速公路”极大地提升了 GPU 协同工作的效率,是当前高性能计算、AI训练和顶级专业图形工作的核心技术之一。
NVLink 的核心优势与价值
在 NVLink 出现之前,多 GPU 系统主要依赖 PCIe(PCI Express)总线进行通信,虽然 PCIe 也在不断升级(如 PCIe 4.0, 5.0),但它本质上是为连接 CPU 和各种外设设计的,GPU 之间通过它通信效率并不高,存在延迟高、带宽瓶颈等问题。
NVLink 的出现解决了这些痛点,其核心优势体现在:
-
极高的带宽
 (图片来源网络,侵删)
(图片来源网络,侵删)- 这是 NVLink 最核心的优势,它提供了远超 PCIe 的数据传输速率。
- 例如:在最新的 NVIDIA H100 GPU 中,NVLink 带宽高达 900 GB/s,而同为 PCIe 5.0 的 x16 带宽仅为约 128 GB/s,这意味着 NVLink 的带宽是 PCIe 5.0 的 7倍以上!
- 高带宽意味着什么? 在 AI 训练中,巨大的神经网络模型需要在多个 GPU 之间频繁地交换参数和梯度,带宽越高,数据交换就越快,训练时间就越短。
-
极低的延迟
- NVLink 提供了 GPU 之间的点对点直接通信,数据无需绕道 CPU,大大缩短了通信延迟。
- 低延迟意味着什么? 在实时渲染或需要即时响应的计算任务中,更短的延迟意味着更快的同步速度,提升了整体系统的响应能力和效率。
-
统一内存空间
- 在支持 NVLink 的系统中,多个 GPU 可以像使用一个巨大的内存池一样,直接访问彼此的显存,一个 GPU 可以读写另一个 GPU 的显存,而无需先将数据复制到系统内存中。
- 统一内存意味着什么? 这极大地简化了编程模型,开发者可以更容易地编写利用多 GPU 并行能力的代码,而无需手动处理复杂的数据搬移,从而释放 GPU 的全部潜能。
NVLink 的工作原理
- 物理连接:通过专用的 NVLink Bridge(桥接器)将两块或多块 NVIDIA GPU 物理连接起来,这些桥接器通常位于显卡的顶部边缘。
- 数据传输:GPU 通过这些专用的高速通道直接交换数据,绕过了传统的 PCIe 总线。
- 系统协同:在操作系统和驱动程序的支持下,系统识别为一个拥有巨大统一内存空间的计算集群,而不是多个独立的 GPU。
支持 NVLink 的 GPU 产品线
NVLink 技术并非所有 NVIDIA GPU 都支持,它主要面向高端、专业和数据中心市场。
消费级/游戏级 GPU
- RTX 30 系列:RTX 3090 / 3090 Ti 是消费级中唯二支持 NVLink 的显卡,它们通过一个 NVLink Bridge 可以实现双卡互联,带宽约为 112.5 GB/s,虽然其初衷更多是为专业内容创作(如 3D 渲染、科学计算)提供巨大显存和带宽,但普通用户也可以尝试用于游戏,不过效果提升有限且兼容性是个问题。
- RTX 20 系列:RTX 2080 / 2080 Ti / Titan RTX 也支持 NVLink。
- RTX 40 系列:非常遗憾,RTX 4090 及其整个 RTX 40 系列均移除了对 NVLink 的硬件支持。 NVIDIA 认为对于大多数游戏玩家来说,性能提升有限,且增加了成本和复杂性,因此决定砍掉此功能。
专业级/数据中心 GPU
- Hopper 架构:NVIDIA H100 (SXM5 和 PCIe 版本),拥有目前最强的 NVLink 能力。
- Ampere 架构:NVIDIA A100 (SXM 版本),是 AI 训练领域的主力。
- Volta 架构:NVIDIA V100 (SXM 版本),是上一代的数据中心旗舰。
- 其他:如 RTX 6000 Ada Generation 等专业显卡也支持 NVLink。
主要应用场景
NVLink 技术的价值在以下场景中体现得淋漓尽致:

-
人工智能 与深度学习
- 大规模模型训练:训练像 GPT-4、PaLM 这样拥有数千亿甚至上万亿参数的巨型语言模型,需要将模型切分到数十甚至上百个 GPU 上进行并行训练,NVLink 的高带宽和低延迟是保证训练效率和可行性的关键。
- 数据并行与模型并行:NVLink 使得不同 GPU 之间高效同步梯度和模型参数成为可能。
-
高性能计算
在科学模拟、气象预测、基因测序、流体力学等领域,需要处理海量的数据集和复杂的计算任务,NVLink 可以将多个 GPU 集群化,形成一个强大的超级计算节点,加速计算过程。
-
专业图形与视觉计算
- 电影特效渲染:渲染一部电影的一个高分辨率镜头可能需要数天甚至数周的时间,使用 NVLink 连接的多 GPU 工作站可以显著缩短渲染时间。
- CAD/CAM 和 3D 建模:处理极其复杂的模型和场景时,NVLink 可以提供流畅的实时预览和更快的模拟计算速度。
-
高性能数据科学
处理和分析 PB 级别的数据集时,利用 NVLink 连接的 GPU 可以加速数据清洗、转换和机器学习模型训练等环节。
与 SLI 的区别
很多人会将 NVLink 与 NVIDIA 旧的 SLI (Scalable Link Interface) 技术混淆,它们虽然都使用桥接器,但目的和原理完全不同:
| 特性 | NVIDIA NVLink | NVIDIA SLI (已废弃) |
|---|---|---|
| 主要目的 | GPU 间数据通信 (用于 AI、HPC、渲染) | 帧渲染分工 (用于提升游戏帧率) |
| 工作模式 | 交换模型参数、梯度、数据块 | 交替渲染一帧画面的不同部分 (AFR) 或不同区域 (SFR) |
| 核心优势 | 高带宽、低延迟 | 在特定游戏中提升帧率 |
| 应用领域 | 专业计算、数据中心、高端创作 | 游戏 |
| 当前状态 | 活跃发展,是未来计算的核心 | 已完全废弃,新一代显卡不再支持 |
NVIDIA NVLink 是一项革命性的技术,它通过为 GPU 间通信打造一条“超级高速公路”,彻底改变了多 GPU 协作的方式。
- 对于普通用户:除了少数几代旗舰游戏显卡(如 RTX 3090)外,你基本接触不到它,对于游戏玩家来说,RTX 40 系列取消 NVLink 影响不大,因为单卡性能已足够强大。
- 对于专业人士和企业:NVLink 是不可或缺的利器,它是训练 AI 大模型、进行科学研究和专业内容创作的基石,能够将多 GPU 的性能潜力发挥到极致,极大地缩短计算时间,降低成本。
随着 AI 和 HPC 需求的爆炸式增长,NVLink 技术的重要性只会越来越高,是衡量顶级计算平台能力的关键指标之一。