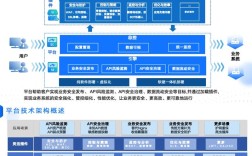
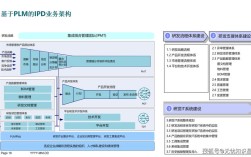
Apple Pay 的核心思想是:用一套极其安全、便捷的数字方式,替代传统钱包里的实体银行卡和现金。 它并非简单地存储银行卡号,而是利用了先进的加密和安全技术,从根本上改变了支付流程。

(图片来源网络,侵删)
我们可以从以下几个层面来理解它的技术原理:
核心架构:三个关键角色
Apple Pay 的运作依赖于三个核心方的协同工作:
- 用户设备:iPhone, Apple Watch, iPad, Mac,这是发起支付的主体。
- 商户:接受 Apple Pay 支付的商店、网站或 App,配备了相应的支付终端或软件。
- 支付网络与银行:如 Visa, Mastercard, 银行等,负责处理交易和资金清算。
这三者通过苹果的生态系统(如 Wallet App)和标准的支付协议(如 EMVCo)连接在一起。
核心安全机制:这是 Apple Pay 的灵魂所在
Apple Pay 的安全性是其能够被广泛接受的关键,它主要依赖于以下四大技术支柱:

(图片来源网络,侵删)
设备账户数字码
这是 Apple Pay 最核心的创新,也是其安全性的基石。
-
是什么?
- 当你添加一张银行卡到 Apple Pay 时,苹果并不会将你的真实银行卡号存储在设备中。
- 相反,苹果会与你的发卡行合作,为这张卡在你的设备上生成一个唯一的、一次性的替代号码,这个号码就是“设备账户数字码”。
- 这个数字码被安全地存储在设备的安全元件中。
-
为什么安全?
- 不泄露真实卡号:在交易过程中,无论是线上还是线下,商户和苹果服务器看到的永远是这个数字码,而不是你的真实银行卡号,这极大地降低了卡号泄露和被盗刷的风险。
- 唯一性:每台设备、每张卡生成的数字码都是独一无二的,即使两台设备添加了同一张银行卡,它们的数字码也不同。
- 本地生成:数字码是在设备的安全元件中生成的,苹果服务器也无法直接获取。
安全元件
这是一个独立的、高度安全的硬件芯片,存在于所有支持 Apple Pay 的设备中(iPhone 7 及更新型号、Apple Watch Series 2 及更新型号等)。

(图片来源网络,侵删)
- 功能:
- 它就像一个设备内部的“保险箱”,专门用来存储最敏感的信息,包括:
- 设备账户数字码
- 支付密钥
- 你的生物信息(面容 ID 的面部数据或触控 ID 的指纹数据,仅用于验证)
- 它与设备的操作系统是隔离的,即使设备系统被完全攻破,攻击者也无法访问安全元件内的数据。
- 所有敏感操作(如生成支付令牌、验证指纹)都在安全元件内部完成,确保了过程的安全性。
- 它就像一个设备内部的“保险箱”,专门用来存储最敏感的信息,包括:
安全令牌化
这个技术将“支付”这个动作,从“验证卡号”变成了“验证一个一次性的、有权限的令牌”。
-
线下支付流程:
- 准备:当你将设备靠近支持 NFC 的支付终端时,终端会发出一个“请求支付”的信号。
- 验证:设备被唤醒,并提示你使用面容 ID 或触控 ID 进行身份验证,这是双重安全的第一层(设备在你手中)。
- 生成令牌:验证通过后,安全元件会生成一个一次性的动态安全码,这个码就是“安全令牌”,它包含了你的设备账户数字码、交易金额、商户信息等,并经过加密。
- 传输:这个安全令牌通过 NFC 技术安全地发送给支付终端。
- 处理:支付终端将这个安全令牌发送给支付网络(如 Visa)。
- 兑换与结算:支付网络认识这个设备账户数字码,它会将令牌兑换回真实的交易信息,然后按照标准的银行卡交易流程发送给你的发卡行进行授权和结算。
-
线上支付流程: 在 Safari 浏览器或 App 内支付时,流程类似,但使用的是 Apple Pay JS API,它会生成一个包含设备账户数字码和交易详情的“支付令牌”,通过 HTTPS 安全地发送给商户的网站或服务器,由商户再提交给支付网络处理。
-
为什么安全?
- 一次性:每个安全令牌只能使用一次,即使这个令牌在传输过程中被截获,也无法被重复使用来发起另一笔交易。
- 无关联:商户无法将这个令牌与你的真实身份或银行卡号关联起来。
生物识别与设备密码
这是双重安全机制的第二层。
- 功能:在发起任何支付前,你必须解锁设备并使用面容 ID、触控 ID 或输入设备密码进行验证。
- 作用:
- 确认是你本人:确保只有设备合法持有人才能发起支付。
- 激活支付:验证通过后,才会启动安全元件去生成和传输安全令牌。
支付场景与流程分解
实体店支付
- 前提:商户支持 NFC 支付(通常有 Apple Pay 标志),你的设备已添加银行卡并处于解锁状态。
- 步骤:
- 唤醒:双击侧边按钮(或 Home 键)打开 Apple Pay。
- 验证:将设备靠近终端,面容 ID / 触控 ID 验证。
- 支付:验证通过,“滴”的一声,支付完成,整个过程通常在 1-2 秒内完成。
App 内支付
- 前提:App 集成了 Apple Pay SDK。
- 步骤:
- 选择:在 App 的支付界面,点击“使用 Apple Pay”。
- 确认:系统会弹出支付摘要,显示金额、商品和默认卡片。
- 验证:通过面容 ID / 触控 ID 或设备密码进行最终确认。
- 完成:支付信息通过 Apple Pay API 安全发送,交易完成。
网页支付
- 前提:在 Safari 浏览器访问支持 Apple Pay 的网站。
- 步骤:
- 选择:在结账页面,点击 Apple Pay 标志。
- 预填:系统会自动填充你的姓名、配送地址和账单地址(可在“设置”中管理)。
- 确认:核对信息,通过面容 ID / 触控 ID 或设备密码确认。
- 完成:支付完成,页面会自动跳转。
隐私保护机制
除了安全,Apple Pay 在隐私方面也做得非常出色:
- 商户无法获取你的信息:商户只知道一笔交易成功了,但不知道你的姓名、地址、邮箱或银行卡号,这些信息只有在你的明确授权下,通过 Apple Pay 的“传递”功能才会提供给商户。
- 苹果不追踪交易:苹果不知道你买了什么,在哪里买的,花了多少钱,苹果的角色是提供一个安全的技术平台,而不是一个数据收集方。
| 特性 | 技术原理 | 带来的好处 |
|---|---|---|
| 替代卡号 | 设备账户数字码 | 商户和交易过程中不暴露真实银行卡号,防泄露。 |
| 安全存储 | 安全元件 | 敏感数据存储在独立的硬件“保险箱”中,防窃取。 |
| 动态验证 | 安全令牌化 | 每次交易使用一次性的动态令牌,防盗刷。 |
| 身份确认 | 生物识别 + 设备密码 | 确保只有本人能发起支付,防滥用。 |
| 便捷支付 | NFC / Apple Pay API | 无需掏出手机、打开 App、输入卡号,体验流畅。 |
| 隐私保护 | 数据最小化原则 | 苹果和商户都无法追踪你的消费行为。 |
Apple Pay 的技术原理是一个精妙的组合,它通过“数字令牌化 + 硬级安全隔离 + 生物识别”的模式,在保证极致便捷的同时,将支付安全性和用户隐私提升到了一个前所未有的高度。